Rule of 72
A colleague and I were talking about local models. Enterprise reticence around sending data to external APIs is real, but open-source alone doesn’t solve it - models need to actually run locally, which means they need to be efficient enough. The hardware will improve, sure. But could today’s state-of-the-art ever run on a phone?
We looked up the Tensor G4 to G5 improvement (Pixel 9 to Pixel 10). About 60% better NPU performance. Bigger than we expected, but not transformative. One generation isn’t going to bridge the gap between a phone and a datacenter.
Then I mentioned the Rule of 72.
Compounding Does Horrifying Things
The Rule of 72 is a shortcut: divide 72 by a growth rate to get the doubling time. At 10% annual growth, you double in about 7 years. At 60% annual growth (like that Pixel improvement), you double in just over a year.
Five years of 60% annual improvement isn’t 5 × 60% = 300%. It’s 1.6^5 = 10x.
Ten years? 100x.
That’s just hardware. Jensen Huang on No Priors this week pointed out there are three curves compounding simultaneously:
“We’re seeing five to 10x every single year. Moore’s law was two times every year and a half. In the case of AI, over the course of 10 years is probably 100,000 to a million x. And that’s just the hardware. Then the next layer is the algorithm layer…”
According to Epoch AI, language model algorithmic efficiency is doubling every 8 months. The Stanford AI Index reports inference costs dropped 280x in two years. DeepSeek trained a frontier model for $5.6M when GPT-4 cost an estimated $78M+.
Hardware improving. Algorithms improving. Architecture improving. All compounding.
What Does That Look Like?
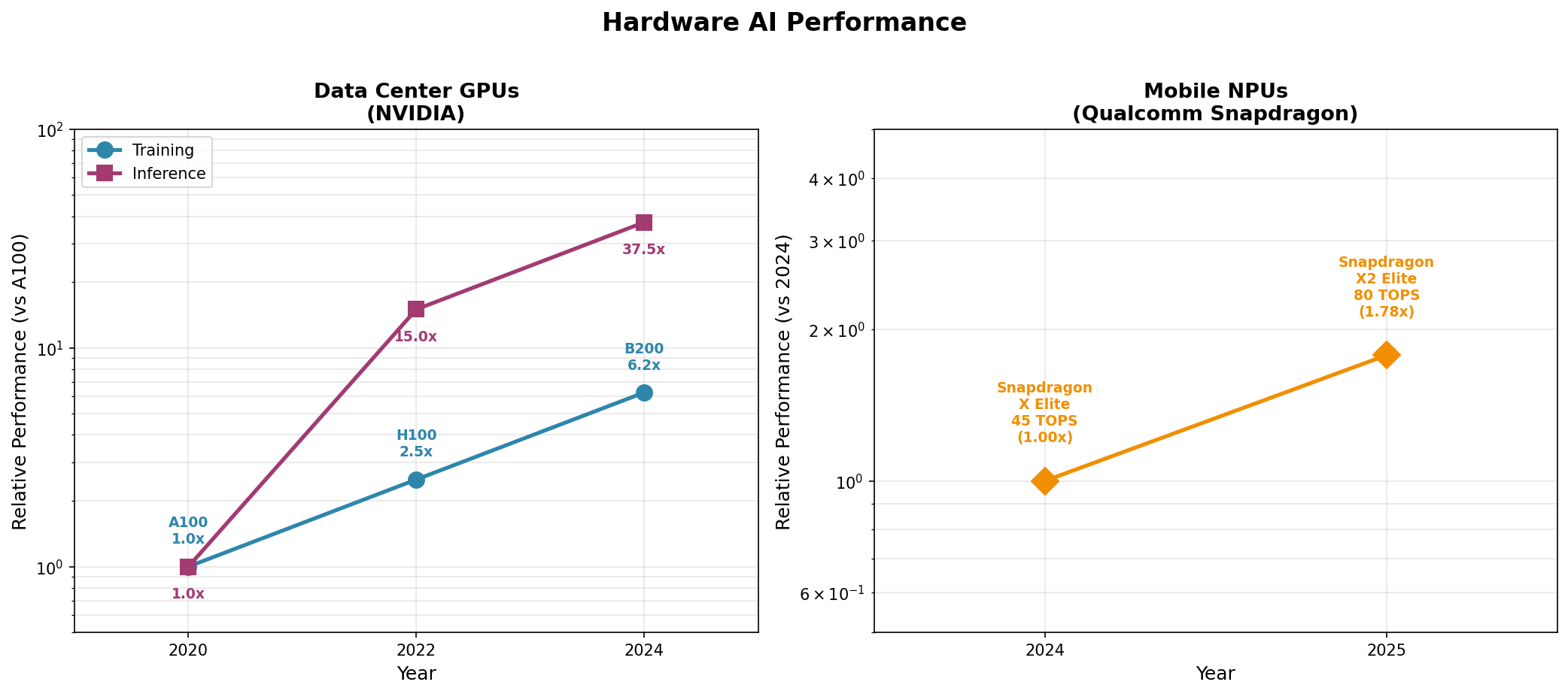
Here’s the hardware curve. Data center GPUs show dramatic gains, especially for inference. Mobile NPUs are improving at ~60% annually - that 1.78x jump from Snapdragon X Elite to X2 Elite in a single year.
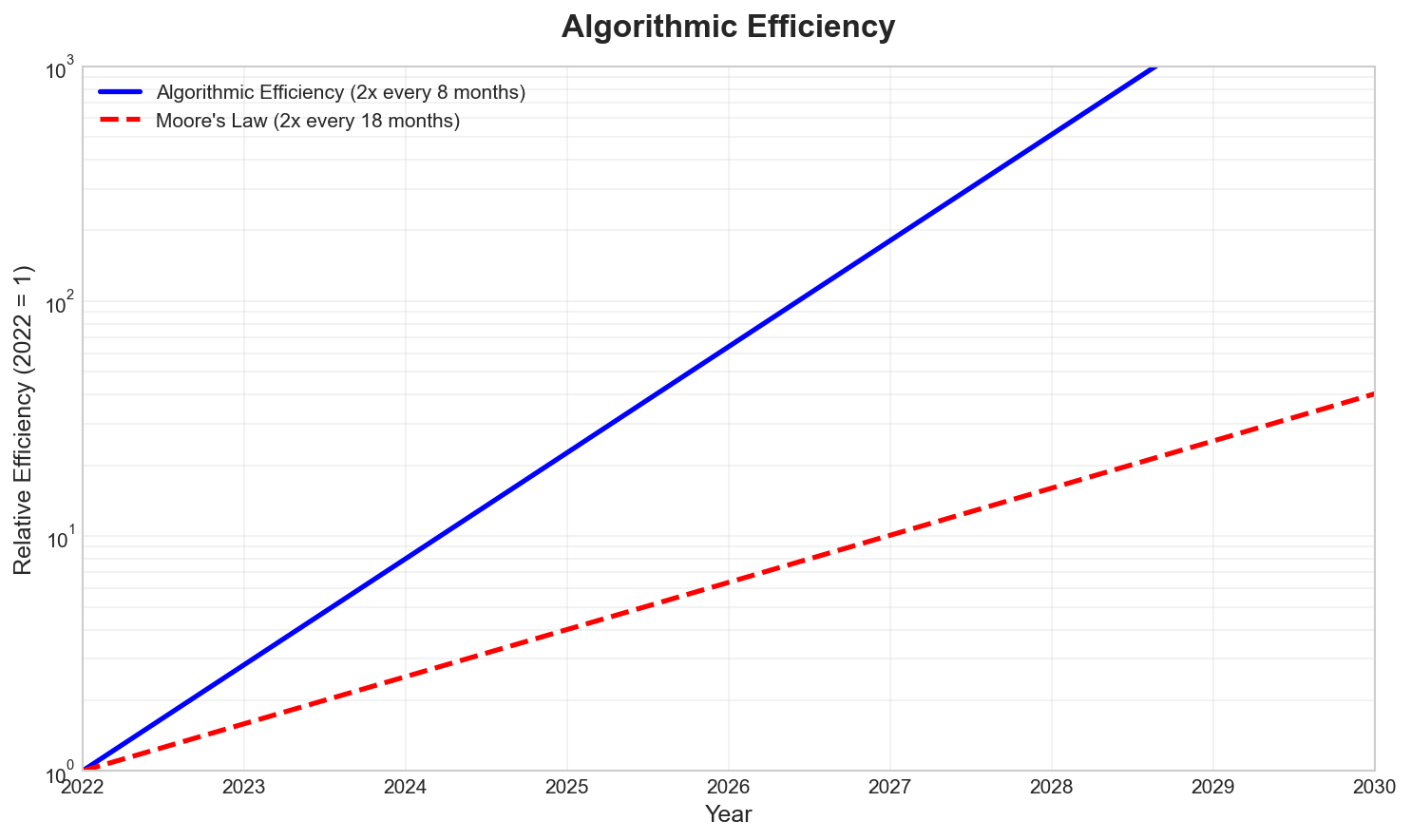
Algorithms are improving even faster. According to Epoch AI, algorithmic efficiency is doubling every 8 months - compared to Moore’s Law’s 18-month doubling time.
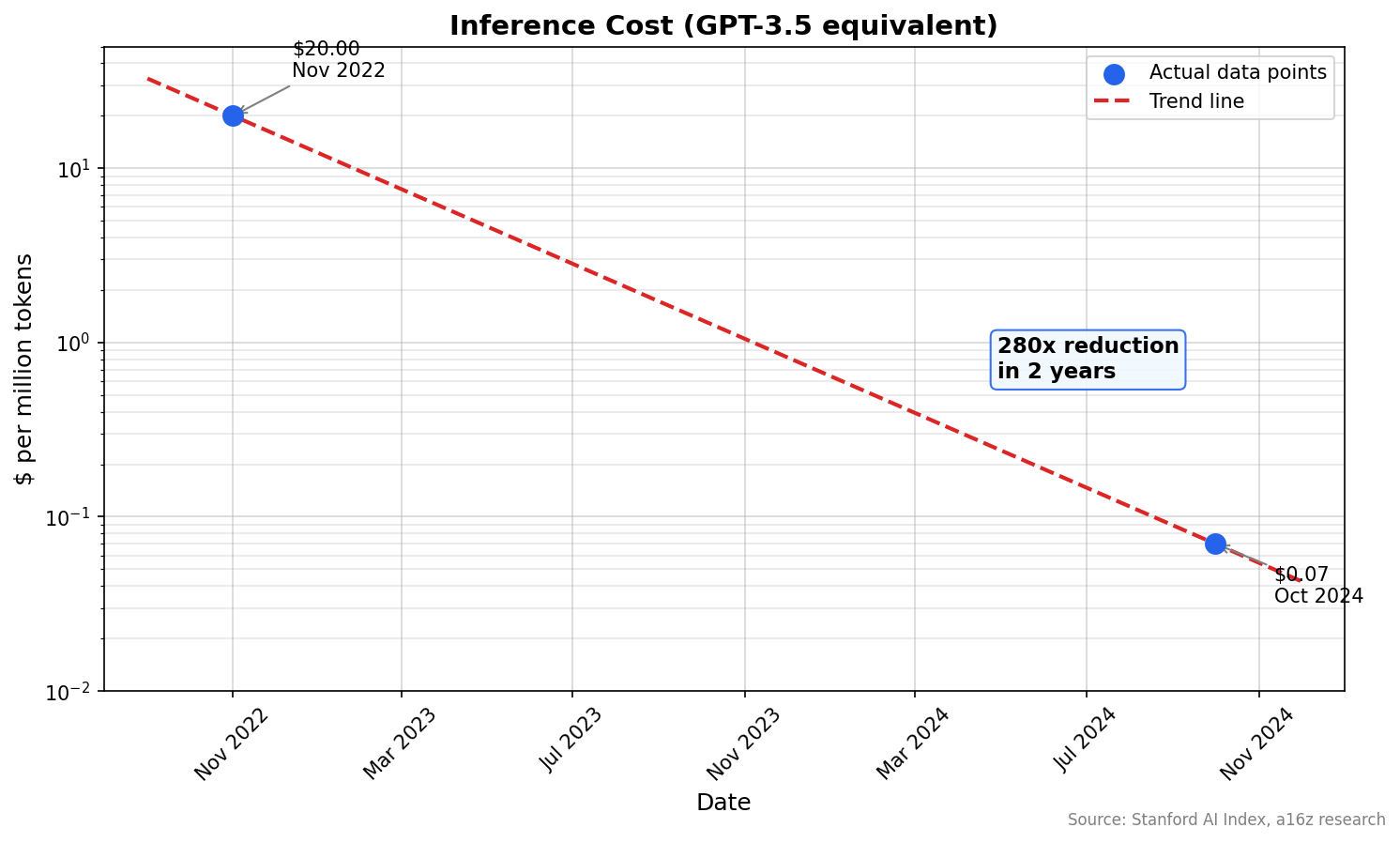
And the combined effect on cost is staggering. GPT-3.5-level inference went from $20 to $0.07 per million tokens in two years.
Jensen’s “100,000 to a million x over 10 years” starts to look less hyperbolic when you see these curves compounding together.
Why This Matters
I don’t really care about AGI timelines. But the steep slope is interesting regardless of where it leads.
The problem with most AI discourse is that people point to what they believe without being specific about what it would entail. “AI will transform everything” or “AI is overhyped” - neither tells you what to actually expect or how to act.
Plotting it out, even crudely, at least lets you think in terms of scenarios. If hardware and algorithms keep compounding at current rates, what does that mean for local inference in 3 years? 5 years? What decisions would you make differently?
The uncomfortable part is that humans are provably bad at intuiting exponentials. Studies during COVID found over 90% of people drastically underestimated infection spread - even educated participants who were explicitly warned about exponential bias. Our heuristics evolved in environments where compound growth was rare.
So when I try to predict forward, I assume my intuitions are wrong. The numbers don’t care what feels reasonable.