The Mask We Can't Drop
I saw a fantastic talk last night at an AI meetup at Jesus College Oxford by Josh Lawman, who runs Adder. One of those that’s enjoyable in the moment and then keeps unfolding in your head afterwards. He was comparing how agentic architectures have evolved over the past couple of years.
He pulled up Anthropic’s “Building Effective Agents” diagrams from late 2024:
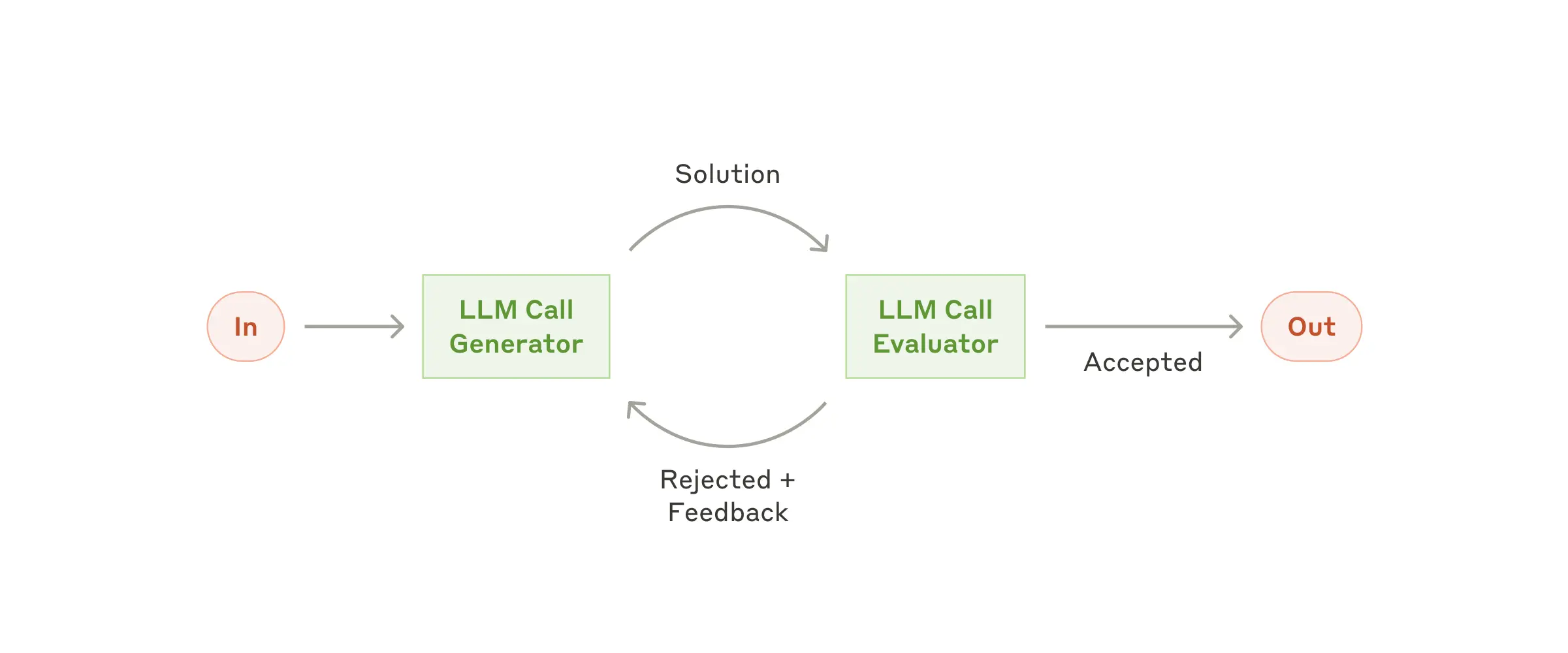
Then he showed what Anthropic’s multi-agent architecture looks like in 2026:
The jump is hard to miss. What was a tidy feedback loop has become an orchestration layer managing parallel workers, state machines, and specialised sub-agents. And that’s just one vendor’s reference architecture. Steve Yegge’s Gas Town has mayors, polecats, witnesses, and refineries. It’s a lot.
Josh briefly demoed Claude Code’s agent teams, currently experimental. Main conversation plus n sub-agent panes in one terminal, changes rippling through. The audience reaction was telling. Unease. “How long to get this set up?” Slight fear. Anthropic and Josh are pointing to something real here, a genuine payoff for the effort. But that unease is a desire line, the same instinct that pushes most people toward GUIs over terminals.
Josh wasn’t making predictions about whether this complexity keeps blooming or simplifies later in the year. He could see it going either way. I felt the same at the time.
But walking home, I kept thinking about the shoggoth meme.

The Lovecraftian horror holding a thin smiley-face mask. Unfathomable alien machinery behind a friendly UI that hides the existential risk.
The meme is becoming more literally true. The shoggoth used to be just the model. Now it’s models plus harnesses: orchestrators, memory systems, tool routers, recursive summarisation. All the machinery we build around context-limited models to squeeze useful work out of them. The chat interface is still the mask. But there’s more tentacles behind it than ever.
Yegge put it well in a recent interview:
Gas Town right now, the reason I say you can’t use it, is that it’s a factory filled with workers and you’re talking to it through a telephone. You can also go and look through the window and pound on it and talk to the workers, but it’s not like you’re in it. With a UI you’re in it, and you can see what’s going on.
He also made the point that most people can’t keep up with walls of text. “To most people, five paragraphs is an essay. That’s the AI just clearing its throat. You’ve got to be able to read waterfalls of text.” It’s almost a terminal-vs-GUI argument: CLI tools assume comfort with text; most users don’t have it.
His prediction: by the end of the year, most people will be programming by talking to a face. Literally an animated character on screen, maybe a fox, that you speak to out loud. You say “why doesn’t it work?” and it says “I’ll go look at it” and spins off workers behind the scenes. Voice in, voice out. The complexity hidden entirely.
So will the shoggoth keep growing? I think there are two forces pushing back.
The first is user demand. People want Apple-like simplicity. Interfaces that induce comfort. The mask isn’t a temporary concession, it’s what users actually prefer. If the choice is between exposing orchestration complexity or hiding it behind a friendly face, the face wins. The elaborate backend might grow, but it’ll stay hidden.
The second is the bitter lesson. Rich Sutton’s famous essay argues that general methods leveraging computation outperform methods encoding human cleverness. The harnesses we’re building (memory systems, tool routers, state machines) are making affordances for the weaknesses of today’s models. They’re human cleverness compensating for limited context and limited reasoning.
But incoming GPU clusters will crush a lot of these problems. When models get smart enough, you’re better off without the harness. The AI portion of the system eats the business logic. The system gets smarter but the plumbing gets simpler.
So: two paths toward simplification. User demand hides the complexity. Scaling removes the need for it.
Unless context windows are a hard constraint.
Reiner Pope from MatX was on a recent podcast:
Long context is one of the biggest bottlenecks on speed of the model. Every single token you generate, it reads through all of the previous tokens… Memory bandwidth for that is really constraining. I think the context size will stay ballpark the same where it is, maybe a few times larger, but the parameter count will go up. Parameter count should grow much faster than context length actually, just because of the underlying physics of what’s available.
If context stays bounded, maybe we’re stuck with the harnesses. The orchestration, the compaction, the recursive summarisation. All downstream of a constraint that isn’t going away.
Will Brown from Prime Intellect was on TBPN recently with a more optimistic take:
Continual learning is going to fall pretty quickly. I think it’s more of an engineering problem… No one’s actually trying. OpenAI and Anthropic don’t want to continuously train their models for each user. It’s expensive and annoying and hard to serve at scale. But from a research perspective, we do continual learning—the model learns new things, they just keep training it more and it knows more stuff. Uneconomical right now, but there’s enough tricks. There doesn’t seem to be any big wall in sight that prevents it from being practical.
So maybe it’s solvable. Maybe it’s just economics. Or maybe context is the wall that the bitter lesson can’t break through.
I don’t know which way this goes. The history of machine learning is overlapping sigmoids. You hit a ceiling, it looks impossible, then someone breaks through. Ilya Sutskever became famous partly for breaking through a series of seemingly impossible ceilings.
But eighteen months is a long time in AI. It’s also not very long at all. Josh was right not to make predictions. The shoggoth will keep growing. The question is whether the mask grows with it, becoming unbelievably elaborate to hide what’s underneath.